- Voxel Meshing for the Rest of us
- How (Not) to Improve Voxel Meshing Performance
- Adding Ambient Occlusion To Our Voxel Mesher
One of the main reasons why I implemented my own voxel mesher in Spacefarer was so I could explore the potential benefits of zero-copy techniques for voxel meshing.
… Zero-copy?
Simply put, an algorithm is zero-copy if it avoids heap allocations entirely and keeps stack allocations minimal. In practice, this means ditching clone and taking references to data instead of copies.
How is this better?
Usually, taking references is significantly faster than cloning data.
As we’re about to find out though, this isn’t always the case:
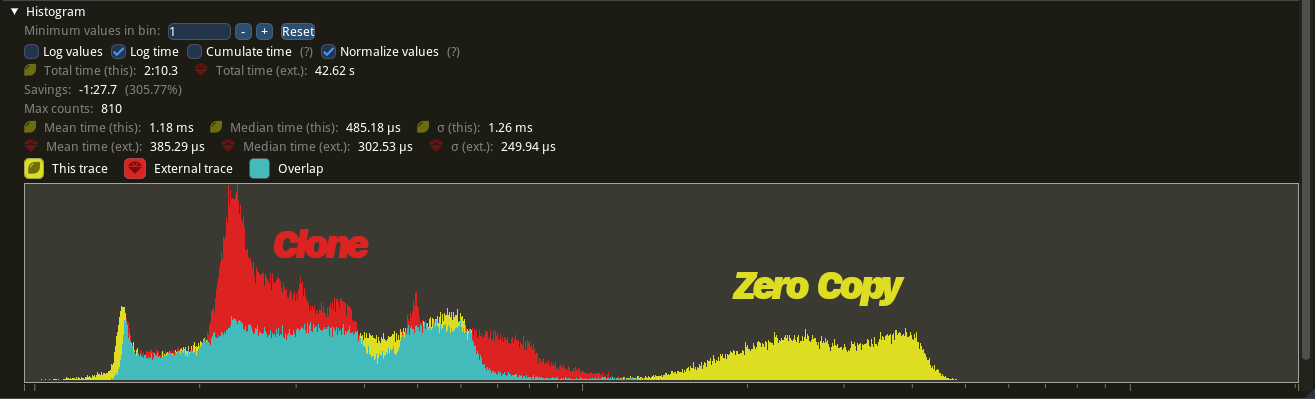
So much for those potential benefits.
Yes, I was expecting to see a performance improvement, not a regression!
So why is zero-copy so much slower?
Good question.
Zero-Copy vs Cloning
Let’s analyze the performance differences between zero-copy and simple cloning.
Zero-Copy
Recall that in order to properly mesh voxel chunks we not only need the data from within a single chunk but we also a single voxel wide slice from each of its six direct neighbors.
In Spacefarer, each chunk is stored individually as a contiguous, heap-allocated array of voxels. When we implement zero-copy meshing for a chunk boundary, we need to take in six references – one for the center and one for each neighboring chunk.
Taking references instead of copying data means that even though the chunks are stored in contiguous chunks, the chunk boundary isn’t. Whenever we ‘index’ into this chunk boundary we will need to do some math and retrieve the corresponding voxel from wherever it may reside:
const CHUNK_SIZE: usize = 16;
const BOUNDARY_SIZE: usize = CHUNK_SIZE + 2;
const EMPTY_VOXEL: Voxel = Voxel::Empty;
pub struct ChunkBoundary<'a> {
center: &'a Chunk,
neighbors: [&'a Chunk; 6]
}
impl<'a> sf_mesher::Chunk for ChunkBoundary<'a> {
type Output = Voxel;
const X: usize = BOUNDARY_SIZE;
const Y: usize = BOUNDARY_SIZE;
const Z: usize = BOUNDARY_SIZE;
fn get(&self, x: usize, y: usize, z: usize) -> Self::Output {
const MAX: usize = CHUNK_SIZE;
const BOUND: usize = MAX + 1;
match (x, y, z) {
(1..=MAX, 1..=MAX, 1..=MAX) => self.center.get(x - 1, y - 1, z - 1),
(BOUND, 1..=MAX, 1..=MAX) => self.neighbors[0].get(0, y - 1, z - 1),
(0, 1..=MAX, 1..=MAX) => self.neighbors[1].get(MAX - 1, y - 1, z - 1),
(1..=MAX, BOUND, 1..=MAX) => self.neighbors[2].get(x - 1, 0, z - 1),
(1..=MAX, 0, 1..=MAX) => self.neighbors[3].get(x - 1, MAX - 1, z - 1),
(1..=MAX, 1..=MAX, BOUND) => self.neighbors[4].get(x - 1, y - 1, 0),
(1..=MAX, 1..=MAX, 0) => self.neighbors[5].get(x - 1, y - 1, MAX - 1),
(_, _, _) => EMPTY_VOXEL,
}
}
}
Let’s see what this looks like in our profiler, over the course of a single frame:

In this profile, we can see that nearly all of the time spent meshing is in the make_quads span.
What is
make_quadsdoing?
Meshing the voxels. It’s named simple_mesh in the original implementation.
During the meshing step each chunk needs to be indexed thousands of times. With the zero-copy implementation, this triggers the match statement every time. This is very slow.
Combined with poor cache locality1Objects laid out closer in memory are faster to access, zero-copy performs significantly worse than a naive approach using clone.
How does that perform?
Let’s take a look.
Cloning
Here is the code for our cloning implementation:
const CHUNK_SIZE: usize = 16;
const BOUNDARY_SIZE: usize = CHUNK_SIZE + 2;
const BOUNDARY_VOXELS: usize = BOUNDARY_SIZE * BOUNDARY_SIZE * BOUNDARY_SIZE;
const EMPTY_VOXEL: Voxel = Voxel::Empty;
pub struct ChunkBoundary {
voxels: Array<Voxel, BOUNDARY_VOXELS>, // Like Box<[T; SIZE]> ...
}
impl sf_mesher::Chunk for ChunkBoundary {
type Output = Voxel;
const X: usize = BOUNDARY_SIZE;
const Y: usize = BOUNDARY_SIZE;
const Z: usize = BOUNDARY_SIZE;
fn get(&self, x: usize, y: usize, z: usize) -> Self::Output {
self.voxels[Self::linearize(x, y, z)]
}
}
impl ChunkBoundary {
pub fn new(center: Chunk, neighbors: [Chunk; 6]) -> Self {
const MAX: usize = CHUNK_SIZE;
const BOUND: usize = MAX + 1;
let voxels = (0..BOUNDARY_VOXELS)
.map(Self::delinearize)
.map(|(x, y, z)| match (x, y, z) {
(1..=MAX, 1..=MAX, 1..=MAX) => center.get(x - 1, y - 1, z - 1),
(BOUND, 1..=MAX, 1..=MAX) => neighbors[0].get(0, y - 1, z - 1),
(0, 1..=MAX, 1..=MAX) => neighbors[1].get(MAX - 1, y - 1, z - 1),
(1..=MAX, BOUND, 1..=MAX) => neighbors[2].get(x - 1, 0, z - 1),
(1..=MAX, 0, 1..=MAX) => neighbors[3].get(x - 1, MAX - 1, z - 1),
(1..=MAX, 1..=MAX, BOUND) => neighbors[4].get(x - 1, y - 1, 0),
(1..=MAX, 1..=MAX, 0) => neighbors[5].get(x - 1, y - 1, MAX - 1),
(_, _, _) => EMPTY_VOXEL,
})
.collect::<Array<Voxel, BOUNDARY_VOXELS>>(); // ... but implements FromIterator
Self { voxels }
}
}In the profiler, over the course of a single frame:

That’s a lot faster. Why?
Let’s take a closer look at one of these spans.
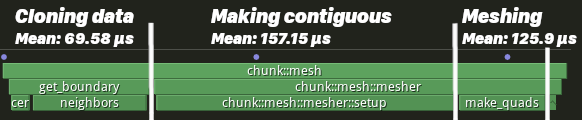
Even though make_quads is the same in both implementations, it is on average 9.3 times faster when we are operating on contiguous, copied data instead of references.
What are the
get_boundaryandsetupspans?
In get_boundary, we retrieve the chunk data and clone it in place. Then in setup, we iterate through each voxel and build a contiguous chunk boundary array.
Takeaways
Even though zero-copy voxel meshing isn’t the right choice for Spacefarer, that might not actually be the case for your game.
There are many variables at play here – from method of chunk storage to size of chunks, or even type of reference taken.
With all those variables, I can’t really tell you whether or not you should use zero-copy meshing in your game.
That’s a cop-out.
Yep.
The real answer is “Try both, benchmark, and see which one performs better for you”.
Still a cop-out.
Fine.
Zero-copy meshing is probably a waste of time. Simply cloning the data is easier to implement and is usually faster.
Still, you should try both! Just so you can prove me wrong.
Good enough.
Is there anything else we can do to improve performance?
Of course.
Avoiding Re-Allocation
Allocation can also be slow, especially when there is high memory pressure.
Let’s take a look at our simple_mesh function – where do we allocate?
pub fn simple_mesh<C, T>(chunk: &C) -> QuadGroups
where
C: Chunk<Output = T>,
T: Voxel,
{
assert!(C::X >= 2);
assert!(C::Y >= 2);
assert!(C::Z >= 2);
let mut buffer = QuadGroups::default();
for i in 0..C::size() {
let (x, y, z) = C::delinearize(i);
if (x > 0 && x < C::X - 1) &&
(y > 0 && y < C::Y - 1) &&
(z > 0 && z < C::Z - 1) {
let voxel = chunk.get(x, y, z);
match voxel.visibility() {
EMPTY => continue,
visibility => {
let neighbors = [
chunk.get(x - 1, y, z),
chunk.get(x + 1, y, z),
chunk.get(x, y - 1, z),
chunk.get(x, y + 1, z),
chunk.get(x, y, z - 1),
chunk.get(x, y, z + 1),
];
for (i, neighbor) in neighbors.into_iter().enumerate() {
let other = neighbor.visibility();
let generate = match (visibility, other) {
(OPAQUE, EMPTY) |
(OPAQUE, TRANSPARENT) |
(TRANSPARENT, EMPTY) => true,
(TRANSPARENT, TRANSPARENT) => {
voxel != neighbor,
}
(_, _) => false,
};
if generate {
buffer.groups[i].push(Quad {
voxel: [x, y, z],
width: 1,
height: 1,
});
}
}
}
}
}
}
buffer
}We allocate in two locations.
The first place is here:
let mut buffer = QuadGroups::default();… and the second place is here:
if generate {
buffer.groups[i].push(Quad {
voxel: [x, y, z],
width: 1,
height: 1,
});
}Let’s create a new function that accepts a mutable reference to a QuadGroups instead of allocating a fresh buffer each time the function is called. We’ll also rework the current function to call the new one behind the scenes:
pub fn simple_mesh<C, T>(chunk: &C) -> QuadGroups
where
C: Chunk<Output = T>,
T: Voxel
{
let mut buffer = QuadGroups::default();
simple_mesh_buffer(chunk, &mut buffer);
buffer
}
pub fn simple_mesh_buffer<C, T>(chunk: &C, buffer: &mut QuadGroups)
where
C: Chunk<Output = T>,
T: Voxel,
{
assert!(C::X >= 2);
assert!(C::Y >= 2);
assert!(C::Z >= 2);
buffer.clear();
for i in 0..C::size() {
let (x, y, z) = C::delinearize(i);
if (x > 0 && x < C::X - 1) &&
(y > 0 && y < C::Y - 1) &&
(z > 0 && z < C::Z - 1) {
let voxel = chunk.get(x, y, z);
match voxel.visibility() {
EMPTY => continue,
visibility => {
let neighbors = [
chunk.get(x - 1, y, z),
chunk.get(x + 1, y, z),
chunk.get(x, y - 1, z),
chunk.get(x, y + 1, z),
chunk.get(x, y, z - 1),
chunk.get(x, y, z + 1),
];
for (i, neighbor) in neighbors.into_iter().enumerate() {
let other = neighbor.visibility();
let generate = match (visibility, other) {
(OPAQUE, EMPTY) |
(OPAQUE, TRANSPARENT) |
(TRANSPARENT, EMPTY) => true,
(TRANSPARENT, TRANSPARENT) => {
voxel != neighbor,
}
(_, _) => false,
};
if generate {
buffer.groups[i].push(Quad {
voxel: [x, y, z],
width: 1,
height: 1,
});
}
}
}
}
}
}
}With this you’ll be able to select either simple_mesh or simple_mesh_buffer based on whatever works better for your project.
Hey, what’s this?
buffer.clear();That’s a new QuadGroups method, let’s implement it:
impl QuadGroups {
// ...
pub fn clear(&mut self) {
self.groups.iter_mut().for_each(|g| g.clear());
}
}How is
Vec::clear()better than just creating a newVec?
If we take a peek at the documentation, this is what we find:
pub fn clear(&mut self)
Clears the vector, removing all values.
Note that this method has no effect on the allocated capacity of the vector.
Vec has both a length (the number of elements) and a capacity (the amount of elements the Vec can store without re-allocating).
If pushing a value to the Vec would exceed the current capacity, new memory is allocated and the capacity is doubled.
Using Vec::clear() removes all items from the Vec without resetting the allocated capacity, so when you push values to the Vec after clear it will not need to allocate until you exceed the current capacity.
In contrast, creating a new Vec allocates a capacity of zero2This may or may not be true, for performance reasons and it is forced to reallocate frequently as you push to it.
… and how is this better than
Vec::with_capacity()?
It’s better because we don’t have to allocate.
What’s performance like?
Let’s see the profile:
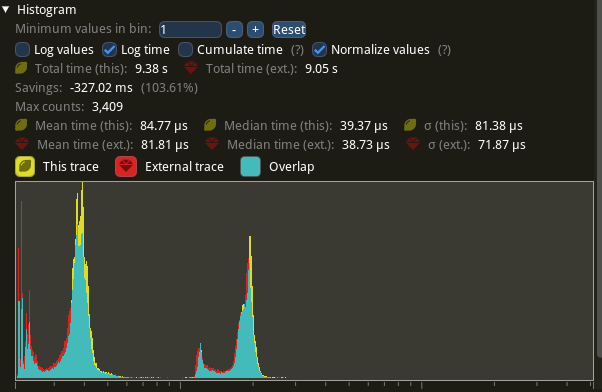
Hooray, it’s … within the margin of error …
Heh.
It’s unfortunate that we didn’t see positive results inside the mesher, but if we implemented buffer re-use in the get_boundary and setup spans (in Spacefarer itself) we would see some minor benefit.
Conclusions
Even though we didn’t make any improvements, failure is often a better teacher than success.
- Good performance is often counter-intuitive, platform-specific, and maybe even device-specific.
- You can’t make any assumptions about what’s fast and what’s slow. To really know for sure you have to profile your game.
- Micro-benchmarks aren’t always trustworthy.
- Complicated implementations aren’t always faster.
- Experimentation is a fantastic way to learn.
In the future, implementing additional features will add significant performance overhead to our mesher. Getting the best possible performance now is important to make sure that implementing these features doesn’t cause our mesher to be too slow to use.
Other Optimizations
This post was written to address performance concerns of the voxel mesher itself.
Here are some other optimizations you may wish to do for your project:
- Enabling LTO (32% performance improvement for Spacefarer)
- Enabling CPU features (SSE / SSSE / AVX / etc)
- Inlining
- Switching to a better Hasher
- Swapping out std types
- … and others found in the Rust Performance Book